

: 데이터를 관리하는 논리적 단위
- 테이블 : Data 저장
- 뷰
- 시퀀스
- 인덱스
- 동의어
==> 위의 모두를 총괄적으로 관리하는 단위 : 스키마 (유저라고 생각하면 됨.)
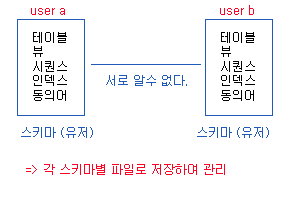
유저를 만든다는것은 위에 5가지를 관리할 집합체를 만드는것이라 생각.
스키마끼리 서로 알수 없다. 서로 접근을 허용을 하지 않았다면 접근할수 없다.
select * from 스키마 employees; 원래는 스키마(유저)가 들어감.
sysdba가 오라클의 최고 사용자와 같음.
sysdba는 다른 스키마도 볼수 있다.
해당 스키마는 저장공간을 명시해 줄수 있다. 파일로 저장되어 관리됨.(저장매체로 접근하는것은 실제로 OS가 하기 때문에)
① 테이블 : DATA저장 ->검색, 수정, 삭제, 제약조건..
컬럼, row을 만듬.
| 컬럼이름 | 데이터형식 | 제약조건 |
|---|---|---|
| 한글도지원 | number | |
| (128개국어지원) | date | |
| char(정해진 문자길이) | ||
| varchar2(가변적늘어남) | ||
| long(최대2G까지가변문자) | ||
| clob(최대4G가지문자데이터) | ||
| blob(가변 길이 이진 데이터(1~4Gbyte)) |
----------테이블 생성------------------------------------------------------------------------------
create table 테이블명(
컬럼 형식 제약조건
);
저장공간 명시
관리기법 명시
----------테이블의 구조 변경-----------------------------------------------------------------------
alter table 테이블명
modify (수정) 컬럼 형식 제약조건
add (추가) 컬럼 형식 제약조건
drop (삭제) 컬럼 형식 제약조건
- 기존의 데이터가 변경할 형식과 다르면 문제가 생김.
ex) alter table employees add yearsal number(15) : 컬럼추가
ex) update employees set yearsal=12*salary+nvl(salary*COMMISSION_PCT,0) ; yearsal에 데이터 추가
----------------------------------------------------------------------------------------------------
create table 사원연봉 as 서브쿼리 : 서브쿼리 내용을 새로운 테이블로 생성!!
ex) create table 사원연봉 as select 12*salary+nvl(salary*COMMISSION_PCT,0) as "연봉" from employees;
----------------------------------------------------------------------------------------------------
cf) unused : 필요없는 컬럼을 사용하지 못하게 만듬. 해당컬럼의 데이터가 많고 데이터베이스가 바쁠때
drop하기 전에 임시방편.
형식 : alter table 테이블명 set unused (컬럼) : unused 설정
형식 : alter table 테이블명 drop unused (컬럼) : unused 된 컬럼을 삭제
--컬럼 UNUSED 하기
ALTER TABLE SAWON SET UNUSED(EMAIL)
ALTER TABLE SAWON SET UNUSED COLUMN EMAIL
--UNUSED상태에 있는 컬럼명 조회
SELECT * FROM USER_UNUSED_COL_TABS
--실제로 UNUSED 상태의 컬럼을 삭제하기
ALTER TABLE SAWON DROP UNUSED COLUMNS
----------------------------------------------------------------------------------------------------
delete : 삭제 (ROLLBACK 가능)
Truncate : 절단 (속도는 delete보다 빠름, ROLLBACK 불가능)
----------------------------------------------------------------------------------------------------
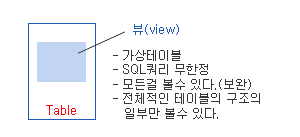
② 뷰 (view)
: 테이블의 논리적인 부분 집합
- 많이 검색하는 쿼리, 컬럼들.. 미리 만들어 둘수 있다.
- DML작업이 많이 없는 것들
- 저장공간을 사용하지 않는다. 즉, 테이블이 아니다??

cf) Top-N 분석 ----------------------------------------------------------------
rownum : row에 대한 number를 붙여줌.
- select rownum,last_name,salary from employees
| ROWNUM | LAST_NAME | SALARY |
|---|---|---|
| 1 | King | 30000 |
| 2 | Kochhar | 17000 |
| 3 | Dehaan | 17000 |
| 4 | Hunold | 9000 |
| 5 | Ernst | 6000 |
| 6 | Lorentz | 4200 |
| 7 | Mourgos | 5800 |
| 8 | Rajs | 3500 |
| 9 | Davies | 3100 |
| 10 | Matos | 2600 |
| 11 | Vargas | 2500 |
| 12 | Zlotkey | 10500 |
| 13 | Abel | 11000 |
| 14 | Taylor | 8600 |
| 15 | Grant | 7000 |
| 16 | Whaien | 4400 |
| 17 | Hartstein | 13000 |
| 18 | Fay | 6000 |
| 19 | Higgins | 12000 |
| 20 | Gietz | 8300 |
- select rownum,last_name,salary from employees order by salary desc;
(먼저 rownum,last_name,salary 를 뽑아 놓고 정렬을 하기때문에, rownum이 뒤죽박죽ㅋㅋ)
| ROWNUM | LAST_NAME | SALARY |
|---|---|---|
| 1 | King | 30000 |
| 2 | Kochhar | 17000 |
| 3 | Dehaan | 17000 |
| 17 | Hartstein | 13000 |
| 19 | Higgins | 12000 |
| 13 | Abel | 11000 |
| 12 | Zlotkey | 10500 |
| 4 | Hunold | 9000 |
| 14 | Taylor | 8600 |
| 20 | Gietz | 8300 |
| 15 | Grant | 7000 |
| 5 | Ernst | 6000 |
| 18 | Fay | 6000 |
| 7 | Mourgos | 5800 |
| 16 | Whaien | 4400 |
| 6 | Lorentz | 4200 |
| 8 | Rajs | 3500 |
| 9 | Davies | 3100 |
| 10 | Matos | 2600 |
| 11 | Vargas | 2500 |
- select rownum,last_name,salary from (select last_name,salary from employees order by salary desc);
| ROWNUM | LAST_NAME | SALARY |
|---|---|---|
| 1 | King | 30000 |
| 2 | Kochhar | 17000 |
| 3 | Dehaan | 17000 |
| 4 | Hartstein | 13000 |
| 5 | Higgins | 12000 |
| 6 | Abel | 11000 |
| 7 | Zlotkey | 10500 |
| 8 | Hunold | 9000 |
| 9 | Taylor | 8600 |
| 10 | Gietz | 8300 |
| 11 | Grant | 7000 |
| 12 | Ernst | 6000 |
| 13 | Fay | 6000 |
| 14 | Mourgos | 5800 |
| 15 | Whaien | 4400 |
| 16 | Lorentz | 4200 |
| 17 | Rajs | 3500 |
| 18 | Davies | 3100 |
| 19 | Matos | 2600 |
| 20 | Vargas | 2500 |
- select rownum,last_name,salary from (select last_name,salary from employees order by salary desc) where rownum<6;
(1~5까지 뽑아보자!!ㅋㅋ)
------------------------------------------------------------------------------------
③ 시퀀스
: 연속적으로 값을 할당하는 의미
ex) Max(employee_id)+1
=> but max는 group 함수, 따라서 row가 많을 수록 시간이 오래 걸림.
이런 단점을 보완해서 나온것이~ 시쿼스라네요~ㅋ
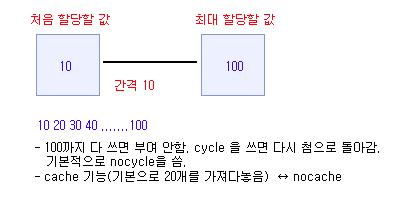
- 형식 : create sequence 시퀀스명 start with 처음부여할번호 increment by 간격 maxvalue 최대값 nocycle nocache ;
ex) - create sequence dept_id_deq start with 200 increment by 10 maxvalue 1000 nocycle nocache;
- select * from user_sequences;
| SEQUENCE_NAME | MIN_VALUE | MAX_VALUE | INCREMENT_BY | CYC | ORD | CACHE_SIZE | LAST_NUMBER |
|---|---|---|---|---|---|---|---|
| DEPT_ID_DEQ | 1 | 1000 | 10 | N | N | 0 | 200 |
- insert into departments values(dept_id_deq.nextval,'KBS',100,1400);
(nextval : last_number의 값을 넣어줌)
| DEPARTMENT_ID | DEPARTMENT_NAME | MANAGER_ID | LOCATION_ID |
|---|---|---|---|
| 200 | KBS | 100 | 1400 |
200 -> currval
210 -> nextval
하나를 더 부여하면,
210 -> currval
220 -> nextval 이 됨.
- insert into departments values(dept_id_deq.nextval,'MBS',600,1100);
| DEPARTMENT_ID | DEPARTMENT_NAME | MANAGER_ID | LOCATION_ID |
|---|---|---|---|
| 200 | KBS | 100 | 1400 |
| 210 | MBS | 600 | 1100 |
cf) 중간에 오류가 나더라도 건너뛰고 자동으로 부여된다.
------------------------------------------------------------------------------------
④ 동의어 (synonym)
긴 이름들을 단순화 할때 쓰면 편리함.
- 형식 : create synonym newname for oldname
참고> 상대방 오라클 접속 설정
1. # xhost + localhost
2. $HOME/bin로 이동 해서
3. $./netca 실행